A Data-Centric Introduction to Python
Previous attendees have said…
- 14 previous attendees have left feedback
- 93% would recommend this session to a colleague
- 100% said that this session was pitched correctly

- could have provided more examples of when to use python over r
- As described on the tin, a slightly chaotic introduction to Python.
- hapPy to see practical contrast of Py with R
A note on this mixed R/Python Quarto file: the text and Python sections were written in a Jupyter notebook, then converted into a Quarto document by:
quarto convert a_data_centric_introduction_to_python.ipynb
R sections, and the tabsets were added, and the document was then knitted using R Quarto in Rstudio by attaching the reticulate (Ushey, Allaire, and Tang 2024) package:
A data-centric introduction to Python
This is a friendly beginner session introducing users to Python. It’s health-and-social-care opinionated, assumes no previous Python knowledge, and will have lots of scope for practical demonstrations. Given that lots of users in the KIND network will have some prior experience of R, we’ll introduce some key Python features by comparison with R
Session structure
- a brief general-purpose chat for intro to the language
- how to read and write Python (jupyter/VS Code/Posit workbench/positron)
- a side-note about Excel Python
- Python for R developers - a practical demonstration
Python introduction
- “Python is a high-level, general-purpose programming language.”
- massive user-base
- highly extensible and flexible (\(10^5\) modules)
- the second-best language for everything
- multi-paradigm (oop, structured, …)
Reading and writing Python
- you’ll need:
- Python, currently at 3.12
- (almost certainly) something to manage modules - like pip or conda
- (almost certainly) an integrated development environment. Loads of options:
- practical demo of Jupyter labs
- non-free use in posit.cloud
- Rstudio via reticulate / Jupyter
- VSCode, which is pretty well industry standard for the wider Python ecosystem
- positron, which is the new kid for data-flavoured Python work
Excel Python
- Python is coming to Excel, apparently…
- roll-out slower than expected
- gives an alternative to VBA etc
- code gets executed in the cloud, so no infrastructure faff…
- but a potential information governance headache
- on the offchance that you have it available,
=PY()is the key function
Python for R people
You’re welcome to follow along using the free basic Python set-up at W3schools
- “hello world!”
- indents vs brackets
- Rmarkdown vs Jupyter
- packages vs modules - for data from csv comparison
- basic work with tabular data - for methods
- vector/tibble/list vs list/tuple/dict/set - for vectorisation vs list comps
- pandas for tabular data
- plotting comparison
“hello world!”
Initially, there’s very little to choose between R and Python, and everything is likely to feel very familiar..
print("hello world!")hello world!1 + 23hw = "hello " + "world" + "!"
hw'hello world!'"hello world"[1] "hello world"1 + 2[1] 3hw <- paste("hello", "world", "!")
hw[1] "hello world !"Indents
- a first big difference: indents matter in Python
- they’re non-optional with proper syntactic function
- broadly correspond to curly brackets in R
word = "care"
if word == "care":
print("I have found someone from care")
else:
print("No, I haven't found anyone from care")I have found someone from careRmarkdown/Quarto vs Jupyter
- Jupyter provides interactive code- and markdown editing. Compare to the render/knit-based workflow of qmd/Rmd
- web-based, so perhaps more like posit.cloud / workbench than Rstudio
- comparatively harder to edit .ipynb files than .Rmd/.qmd in other tools
Packages vs modules
We’ll load the pandas module in Python, and the readr package in R (Wickham, Hester, and Bryan 2024) to compare and contrast loading external functions. We’ll use those to read some sample data (the KIND book of the week dataset).
botw_dat = "https://raw.githubusercontent.com/NES-DEW/KIND-community-standards/main/data/KIND_book_of_the_week.csv"
import pandas
botw = pandas.read_csv(botw_dat)But we also have a lot of options for loading modules. We can alias, most usefully to give us short names for commonly-used functions:
import pandas as pd
botw = pd.read_csv(botw_dat)We could even load an individual function from a module:
from pandas import read_csv as read_csv
botw = read_csv(botw_dat)
# one minor bit of cheating - we'll coerce the Year column to numeric
botw = botw.replace("1979 (1935)", 1979)
botw = botw.replace("2015 / 2017", 2015)
botw["Year"] = pandas.to_numeric(botw["Year"])There are comparatively fewer options for package loading in R. You’d traditionally attach a whole package using library:
You can load individual functions by namespacing via :::
botw <- readr::read_csv(botw_dat)It is also possible, although non-standard, to alias individual functions:
steve <- readr::read_csv
botw <- steve(botw_dat)Fun with tabular data
Doing some basic playing with our tabular data shows that Python uses methods - like a local version of a functions that are specific to certain types of object. While methods can be used in R, in practice most R code relies on functions.
Data types
- there are four basic data types in Python
- list
- tuple
- dict
- set
numbers_list = [1,2,3,4,5] # changeable
numbers_list[1, 2, 3, 4, 5]numbers_tuple = (1,2,3,4,5) # unchangeable
numbers_tuple(1, 2, 3, 4, 5)numbers_dict = {"one":1, "two":2, "three":3} # changeable (now), no duplicates
numbers_dict{'one': 1, 'two': 2, 'three': 3}numbers_set = {1,2,3,4,5} # unchangeable, no duplicates
numbers_set{1, 2, 3, 4, 5}# Modify in place semantics
numbers_list.reverse()- R has several basic data types, but in practice only three are commonly encountered. These are the vector, the data frame, and the list (confusing!):
numbers_vector <- c(1,2,3,4,5)
numbers_vector[1] 1 2 3 4 5numbers_dataframe <- data.frame(nums = numbers_vector)
numbers_dataframe nums
1 1
2 2
3 3
4 4
5 5numbers_list <- list(numbers_vector, numbers_dataframe)
numbers_list[[1]]
[1] 1 2 3 4 5
[[2]]
nums
1 1
2 2
3 3
4 4
5 5Loops, list comprehensions, and vectorization
There are various methods for repeatedly running code. We’ll demonstrate a couple of simple methods here. Note that both Python and R have rich and powerful functional programming tools available (like map), but we’ll park those for now.
You’ll need to use loops, or (much nicer) list comprehension in Python. There’s no exact counterpart of R’s vectorized functions:
double_numbers_loop = []
for n in numbers_list:
double_numbers_loop.append(n * 2)
double_numbers_loop[10, 8, 6, 4, 2]List comprehension
Like a lovely lightweight loop syntax
double_numbers_list = [n*2 for n in numbers_list]
double_numbers_list[10, 8, 6, 4, 2]# and, more fancy...
double_even_numbers_list = [n*2 for n in numbers_list if (n%2 == 0) ]
double_even_numbers_list[8, 4]By and large, R is at its best with vectorized functions:
double_numbers_vector <- numbers_vector * 2
double_numbers_vector[1] 2 4 6 8 10Loops are possible too
R has copy-on-modify semantics, and so care needs to be taken to avoid writing poorly-performing loops. That means that loops are used comparatively rarely in R.
Tabular data basics
- we’ll do a quick overview of pandas, based on their excellent 10 minute overview
- our
botwobject is a DataFrame, which is based on a dict- like tibbles, DataFrames can contain columns of different types
botw.dtypes # find out what we're dealing withDate object
Author object
Year int64
Title object
ISBN object
Worldcat object
KnowledgeNetwork object
Description object
dtype: objectbotw.head() # shows first few rows Date ... Description
0 06/03/2024 ... The Code Book: The Secret History of Codes and...
1 13/03/2024 ... Here's a book of the week suggestion following...
2 20/03/2024 ... NaN
3 27/03/2024 ... NaN
4 24/04/2024 ... We're looking at regular expressions in the co...
[5 rows x 8 columns]botw.index # effectively counts rowsRangeIndex(start=0, stop=40, step=1)botw.columns # gives column namesIndex(['Date', 'Author', 'Year', 'Title', 'ISBN', 'Worldcat',
'KnowledgeNetwork', 'Description'],
dtype='object')botw.describe() # simple summary Year
count 40.000000
mean 2009.450000
std 13.254801
min 1954.000000
25% 2005.500000
50% 2012.000000
75% 2018.000000
max 2023.000000botw.sort_values("Year") # sorting by column values Date ... Description
20 21/08/2024 ... This week's book of the week was suggested by ...
9 29/05/2024 ... If last week's book was a paean to the use of ...
2 20/03/2024 ... NaN
6 08/05/2024 ... After the discussion last week about the troub...
0 06/03/2024 ... The Code Book: The Secret History of Codes and...
15 10/07/2024 ... There are a lot of statistics textbooks out th...
13 26/06/2024 ... We're still on a mini-exploration of manufactu...
12 19/06/2024 ... Last week's recommendation about agnotology sp...
26 02/10/2024 ... How do you communicate risks? For many of us w...
10 05/06/2024 ... It's now close to twenty years old, and deals ...
28 06/11/2024 ... This week's recommendation comes from Alupha C...
39 21/02/2025 ... We're running a hints-and-tips training sessio...
21 28/08/2024 ... This week's book of the week was suggested by ...
7 15/05/2024 ... If I was posh enough to have a Latin motto, it...
32 04/12/2024 ... Nicholas Fethers, a Senior Information Analyst...
1 13/03/2024 ... Here's a book of the week suggestion following...
22 04/09/2024 ... This week's book of the week was suggested by ...
38 14/02/2025 ... This is a remarkable book, which gathers toget...
18 07/08/2024 ... This is an excellent introduction to disease g...
16 17/07/2024 ... This book suggestion comes from a conversation...
34 17/01/2025 ... This week's book of the week is a personal rec...
11 12/06/2024 ... While the word [agnotology](https://simple.wik...
19 14/08/2024 ... This is a fun and thought-provoking set of ess...
35 24/01/2025 ... Ebrahim Ghaderi, a healthcare scientist at Pub...
3 27/03/2024 ... NaN
17 31/07/2024 ... If you've ever been stunned by an unexpectedly...
36 31/01/2025 ... Brian Orpin, a team manager from PHS writes wi...
31 27/11/2024 ... Colin Smith, an information analyst at NHS GGC...
4 24/04/2024 ... We're looking at regular expressions in the co...
8 22/05/2024 ... A love-letter to the power of domain knowledge...
14 03/07/2024 ... This week's BotW suggestion comes from Anna Sc...
5 01/05/2024 ... Anyone who works with data knows that our data...
23 11/09/2024 ... Rosalyn Pearson, a Senior Information Analyst ...
24 18/09/2024 ... A possibly-controversial choice this week, wit...
29 13/11/2024 ... This is a high-risk recommendation, because I'...
30 20/11/2024 ... This week's recommendation comes from Louise S...
25 25/09/2024 ... A recommendation this week from Vasudha Singh,...
27 30/10/2024 ... This week's recommendation comes from Kelsey P...
33 10/01/2025 ... Rita Nogueira, a Senior Information Analyst ...
37 07/02/2025 ... We get asked for helpful R resources very regu...
[40 rows x 8 columns]botw["Date"] # selecting a column and creating a series0 06/03/2024
1 13/03/2024
2 20/03/2024
3 27/03/2024
4 24/04/2024
5 01/05/2024
6 08/05/2024
7 15/05/2024
8 22/05/2024
9 29/05/2024
10 05/06/2024
11 12/06/2024
12 19/06/2024
13 26/06/2024
14 03/07/2024
15 10/07/2024
16 17/07/2024
17 31/07/2024
18 07/08/2024
19 14/08/2024
20 21/08/2024
21 28/08/2024
22 04/09/2024
23 11/09/2024
24 18/09/2024
25 25/09/2024
26 02/10/2024
27 30/10/2024
28 06/11/2024
29 13/11/2024
30 20/11/2024
31 27/11/2024
32 04/12/2024
33 10/01/2025
34 17/01/2025
35 24/01/2025
36 31/01/2025
37 07/02/2025
38 14/02/2025
39 21/02/2025
Name: Date, dtype: objectbotw[2:4] # subsetting by index using a slice and returning a DataFrame Date Author ... KnowledgeNetwork Description
2 20/03/2024 David Oldroyd ... NaN NaN
3 27/03/2024 Katrine Marcal ... NaN NaN
[2 rows x 8 columns]botw[["Date"]] # subsetting entire columns Date
0 06/03/2024
1 13/03/2024
2 20/03/2024
3 27/03/2024
4 24/04/2024
5 01/05/2024
6 08/05/2024
7 15/05/2024
8 22/05/2024
9 29/05/2024
10 05/06/2024
11 12/06/2024
12 19/06/2024
13 26/06/2024
14 03/07/2024
15 10/07/2024
16 17/07/2024
17 31/07/2024
18 07/08/2024
19 14/08/2024
20 21/08/2024
21 28/08/2024
22 04/09/2024
23 11/09/2024
24 18/09/2024
25 25/09/2024
26 02/10/2024
27 30/10/2024
28 06/11/2024
29 13/11/2024
30 20/11/2024
31 27/11/2024
32 04/12/2024
33 10/01/2025
34 17/01/2025
35 24/01/2025
36 31/01/2025
37 07/02/2025
38 14/02/2025
39 21/02/2025botw.loc[4] # subsetting by index using a slice and returning a seriesDate 24/04/2024
Author Tom Lean
Year 2016
Title Electronic Dreams: How 1980s Britain Learned t...
ISBN 978-1472918338
Worldcat https://search.worldcat.org/title/907966036
KnowledgeNetwork NaN
Description We're looking at regular expressions in the co...
Name: 4, dtype: objectbotw.loc[4, ["Author", "Year"]] # subsetting by index and columns and returning a DataFrameAuthor Tom Lean
Year 2016
Name: 4, dtype: objectbotw[botw["Year"] > 2010].sort_values("Year") # subsetting by years, and sorting Date ... Description
1 13/03/2024 ... Here's a book of the week suggestion following...
18 07/08/2024 ... This is an excellent introduction to disease g...
22 04/09/2024 ... This week's book of the week was suggested by ...
38 14/02/2025 ... This is a remarkable book, which gathers toget...
16 17/07/2024 ... This book suggestion comes from a conversation...
11 12/06/2024 ... While the word [agnotology](https://simple.wik...
34 17/01/2025 ... This week's book of the week is a personal rec...
19 14/08/2024 ... This is a fun and thought-provoking set of ess...
35 24/01/2025 ... Ebrahim Ghaderi, a healthcare scientist at Pub...
17 31/07/2024 ... If you've ever been stunned by an unexpectedly...
4 24/04/2024 ... We're looking at regular expressions in the co...
36 31/01/2025 ... Brian Orpin, a team manager from PHS writes wi...
31 27/11/2024 ... Colin Smith, an information analyst at NHS GGC...
3 27/03/2024 ... NaN
14 03/07/2024 ... This week's BotW suggestion comes from Anna Sc...
8 22/05/2024 ... A love-letter to the power of domain knowledge...
5 01/05/2024 ... Anyone who works with data knows that our data...
23 11/09/2024 ... Rosalyn Pearson, a Senior Information Analyst ...
24 18/09/2024 ... A possibly-controversial choice this week, wit...
29 13/11/2024 ... This is a high-risk recommendation, because I'...
30 20/11/2024 ... This week's recommendation comes from Louise S...
25 25/09/2024 ... A recommendation this week from Vasudha Singh,...
27 30/10/2024 ... This week's recommendation comes from Kelsey P...
33 10/01/2025 ... Rita Nogueira, a Senior Information Analyst ...
37 07/02/2025 ... We get asked for helpful R resources very regu...
[25 rows x 8 columns]botw[botw["Author"].isin(["Katrine Marçal", "Caroline Criado Perez"])] # finding matching values Date ... Description
5 01/05/2024 ... Anyone who works with data knows that our data...
[1 rows x 8 columns]botw.dropna() # removes any missing values in the whole DataFrame Date ... Description
11 12/06/2024 ... While the word [agnotology](https://simple.wik...
14 03/07/2024 ... This week's BotW suggestion comes from Anna Sc...
15 10/07/2024 ... There are a lot of statistics textbooks out th...
17 31/07/2024 ... If you've ever been stunned by an unexpectedly...
20 21/08/2024 ... This week's book of the week was suggested by ...
22 04/09/2024 ... This week's book of the week was suggested by ...
23 11/09/2024 ... Rosalyn Pearson, a Senior Information Analyst ...
26 02/10/2024 ... How do you communicate risks? For many of us w...
30 20/11/2024 ... This week's recommendation comes from Louise S...
[9 rows x 8 columns]botw["Title"].str.lower() # returning the title column as a lower-case series0 the code book
1 ghost in the wires
2 the arch of knowledge
3 who cooked adam smith's dinner
4 electronic dreams: how 1980s britain learned t...
5 invisible women: exposing data bias in a world...
6 the mismeasure of man (2nd ed)
7 being wrong: adventures in the margin of error
8 bad blood: secrets and lies in a silicon valle...
9 genesis and development of a scientific fact
10 in the beginning was the worm: finding the sec...
11 merchants of doubt
12 harvey's heart: the discovery of blood circula...
13 dark remedy: the impact of thalidomide and its...
14 how emotions are made
15 medical statistics at a glance
16 the half-life of facts
17 weapons of math destruction
18 disease maps: epidemics on the ground
19 the utopia of rules: on technology, stupidity,...
20 how to lie with statistics
21 "clean code: a handbook of agile software cra...
22 thinking, fast and slow
23 the 7 deadly sins of psychology
24 what tech calls thinking: an inquiry into the ...
25 how do you know if you are making a difference...
26 reckoning with risk: learning to live with unc...
27 hybrid humans: dispatches from the frontiers o...
28 asking the right questions: a guide to critica...
29 the alignment problem
30 the devil you know - encounters in forensic ps...
31 the end of alchemy: money, banking and the fut...
32 the checklist manifesto
33 technofeudalism
34 the geek manifesto
35 'sapiens: a brief history of humankind' and 'h...
36 never split the difference
37 r for data science (2nd edition)
38 field notes on science & nature
39 how to write a lot
Name: Title, dtype: objectbotw["Date"] = pandas.to_datetime(botw["Date"],format='%d/%m/%Y') # fixing publication dates
botw.groupby(pd.DatetimeIndex(botw['Date']).month)[["Year"]].mean("Year") # average year of publication by month of botw Year
Date
1 2016.500000
2 2013.666667
3 2003.000000
4 2016.000000
5 2004.400000
6 2004.500000
7 2011.500000
8 1997.000000
9 2018.000000
10 2012.000000
11 2015.750000
12 2010.000000spc_tbl_ [40 × 8] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
$ Date : chr [1:40] "06/03/2024" "13/03/2024" "20/03/2024" "27/03/2024" ...
$ Author : chr [1:40] "Simon Singh" "Kevin Mitnick" "David Oldroyd" "Katrine Marcal" ...
$ Year : chr [1:40] "1999" "2011" "1986" "2016" ...
$ Title : chr [1:40] "The Code Book" "Ghost in the Wires" "The Arch of Knowledge" "Who Cooked Adam Smith's Dinner" ...
$ ISBN : chr [1:40] "978-1857028898" "978-0316037723" "978-0416013313" "978-1846275661" ...
$ Worldcat : chr [1:40] "https://search.worldcat.org/title/59579840" "https://search.worldcat.org/title/773175688" "https://search.worldcat.org/title/12663957" "https://search.worldcat.org/title/933444501" ...
$ KnowledgeNetwork: chr [1:40] NA NA NA NA ...
$ Description : chr [1:40] "The Code Book: The Secret History of Codes and Code-Breaking a book by . (bookshop.org) (to buy online but supp"| __truncated__ "Here's a book of the week suggestion following on from the codes theme from last time. It's the autobiography o"| __truncated__ NA NA ...
- attr(*, "spec")=
.. cols(
.. Date = col_character(),
.. Author = col_character(),
.. Year = col_character(),
.. Title = col_character(),
.. ISBN = col_character(),
.. Worldcat = col_character(),
.. KnowledgeNetwork = col_character(),
.. Description = col_character()
.. )
- attr(*, "problems")=<externalptr> head(botw) # shows first few rows# A tibble: 6 × 8
Date Author Year Title ISBN Worldcat KnowledgeNetwork Description
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 06/03/2024 Simon Singh 1999 The … 978-… https:/… <NA> The Code B…
2 13/03/2024 Kevin Mitn… 2011 Ghos… 978-… https:/… <NA> Here's a b…
3 20/03/2024 David Oldr… 1986 The … 978-… https:/… <NA> <NA>
4 27/03/2024 Katrine Ma… 2016 Who … 978-… https:/… <NA> <NA>
5 24/04/2024 Tom Lean 2016 Elec… 978-… https:/… <NA> We're look…
6 01/05/2024 Caroline C… 2019 Invi… 978-… https:/… <NA> Anyone who…nrow(botw) # counts rows[1] 40names(botw) # column names[1] "Date" "Author" "Year" "Title"
[5] "ISBN" "Worldcat" "KnowledgeNetwork" "Description" summary(botw) Date Author Year Title
Length:40 Length:40 Length:40 Length:40
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
ISBN Worldcat KnowledgeNetwork Description
Length:40 Length:40 Length:40 Length:40
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character botw |>
arrange(Year) # native pipe operator in R. Piped code in Python requires modules# A tibble: 40 × 8
Date Author Year Title ISBN Worldcat KnowledgeNetwork Description
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 21/08/2024 Darrell H… 1954 How … 978-… https:/… https://nhs.pri… "This week…
2 29/05/2024 Ludwig Fl… 1979… Gene… 978-… https:/… <NA> "If last w…
3 20/03/2024 David Old… 1986 The … 978-… https:/… <NA> <NA>
4 08/05/2024 Stephen J… 1996 The … 978-… https:/… <NA> "After the…
5 06/03/2024 Simon Sin… 1999 The … 978-… https:/… <NA> "The Code …
6 10/07/2024 Aviva Pet… 2000 Medi… 978-… https:/… https://nhs.pri… "There are…
7 19/06/2024 Andrew Gr… 2001 Harv… 978-… https:/… <NA> "Last week…
8 26/06/2024 Trent D. … 2001 Dark… 978-… https:/… <NA> "We're sti…
9 02/10/2024 Gerd Gige… 2002 Reck… 978-… https:/… https://nhs.pri… "How do yo…
10 05/06/2024 Andrew Br… 2004 In t… 978-… https:/… <NA> "It's now …
# ℹ 30 more rowsbotw$Date # selecting a column as a vector [1] "06/03/2024" "13/03/2024" "20/03/2024" "27/03/2024" "24/04/2024"
[6] "01/05/2024" "08/05/2024" "15/05/2024" "22/05/2024" "29/05/2024"
[11] "05/06/2024" "12/06/2024" "19/06/2024" "26/06/2024" "03/07/2024"
[16] "10/07/2024" "17/07/2024" "31/07/2024" "07/08/2024" "14/08/2024"
[21] "21/08/2024" "28/08/2024" "04/09/2024" "11/09/2024" "18/09/2024"
[26] "25/09/2024" "02/10/2024" "30/10/2024" "06/11/2024" "13/11/2024"
[31] "20/11/2024" "27/11/2024" "04/12/2024" "10/01/2025" "17/01/2025"
[36] "24/01/2025" "31/01/2025" "07/02/2025" "14/02/2025" "21/02/2025"botw |>
slice(3:4) # subsetting by index using slice and returning a tibble Note different indexing behaviour# A tibble: 2 × 8
Date Author Year Title ISBN Worldcat KnowledgeNetwork Description
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 20/03/2024 David Oldr… 1986 The … 978-… https:/… <NA> <NA>
2 27/03/2024 Katrine Ma… 2016 Who … 978-… https:/… <NA> <NA> botw |>
select(Date) # subsetting entire columns# A tibble: 40 × 1
Date
<chr>
1 06/03/2024
2 13/03/2024
3 20/03/2024
4 27/03/2024
5 24/04/2024
6 01/05/2024
7 08/05/2024
8 15/05/2024
9 22/05/2024
10 29/05/2024
# ℹ 30 more rowsas.character(botw[5,]) # subsetting by index and coercing to a vector. This is pretty non-idiomatic in R[1] "24/04/2024"
[2] "Tom Lean"
[3] "2016"
[4] "Electronic Dreams: How 1980s Britain Learned to Love the Computer"
[5] "978-1472918338"
[6] "https://search.worldcat.org/title/907966036"
[7] NA
[8] "We're looking at regular expressions in the community meetup today. Regex, as the wikipedia page suggests, have been around for ages - positively archaeological in computing terms. So for the book of the week this week, I wanted to show off one of the most interesting bits of social history I've read: Tom Lean's Electronic Dreams. Lots of the history of computing is either primarily about the technical details, or is a broadly nostalgic look at obsolete tech. This book doesn't do either of those, instead spending its time giving a concise account of how personal computing worked as a social phenomenon. For example, how did people start getting paid to write computer games? What happened when the BBC got involved in personal computing? What happened to the various promises of digital revolutions as a replacement for manufacturing industries."botw[5,] |>
select(Author, Year) # subsetting by index and columns and returning a tibble# A tibble: 1 × 2
Author Year
<chr> <chr>
1 Tom Lean 2016 botw |>
filter(Year > 2010) |>
arrange(Year) # subsetting by filtering years, then sorting using dplyr# A tibble: 25 × 8
Date Author Year Title ISBN Worldcat KnowledgeNetwork Description
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 13/03/2024 Kevin Mit… 2011 Ghos… 978-… https:/… <NA> Here's a b…
2 07/08/2024 Tom Koch 2011 Dise… 978-… https:/… <NA> This is an…
3 04/09/2024 Daniel Ka… 2011 Thin… 978-… https:/… https://nhs.pri… This week'…
4 14/02/2025 Michael C… 2011 Fiel… 978-… https:/… <NA> This is a …
5 12/06/2024 Naomi Ore… 2012 Merc… 978-… https:/… https://nhs.pri… While the …
6 17/07/2024 Samuel Ar… 2012 The … 978-… https:/… <NA> This book …
7 17/01/2025 Mark Hend… 2012 The … 978-… https:/… <NA> This week'…
8 14/08/2024 David Gra… 2015 The … 978-… https:/… <NA> This is a …
9 24/01/2025 Yuval Noa… 2015… 'Sap… 978-… https:/… <NA> Ebrahim Gh…
10 27/03/2024 Katrine M… 2016 Who … 978-… https:/… <NA> <NA>
# ℹ 15 more rowsbotw[which(botw$Author %in% c("Katrine Marçal", "Caroline Criado Perez")),] # finding matching values using base R# A tibble: 1 × 8
Date Author Year Title ISBN Worldcat KnowledgeNetwork Description
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 01/05/2024 Caroline C… 2019 Invi… 978-… https:/… <NA> Anyone who…botw |>
tidyr::drop_na() # removes any missing values in the whole tibble# A tibble: 9 × 8
Date Author Year Title ISBN Worldcat KnowledgeNetwork Description
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 12/06/2024 Naomi Ores… 2012 Merc… 978-… https:/… https://nhs.pri… While the …
2 03/07/2024 Lisa Feldm… 2018 How … 978-… https:/… https://nhs.pri… This week'…
3 10/07/2024 Aviva Petr… 2000 Medi… 978-… https:/… https://nhs.pri… There are …
4 31/07/2024 Cathy O'Ne… 2016 Weap… 978-… https:/… https://nhs.pri… If you've …
5 21/08/2024 Darrell Hu… 1954 How … 978-… https:/… https://nhs.pri… This week'…
6 04/09/2024 Daniel Kah… 2011 Thin… 978-… https:/… https://nhs.pri… This week'…
7 11/09/2024 Chris Cham… 2019 The … 978-… https:/… https://nhs.pri… Rosalyn Pe…
8 02/10/2024 Gerd Giger… 2002 Reck… 978-… https:/… https://nhs.pri… How do you…
9 20/11/2024 Gwen Adshe… 2021 The … 978-… https:/… https://nhs.pri… This week'…botw$Title |>
tolower() # returning the title column as a lower-case vector [1] "the code book"
[2] "ghost in the wires"
[3] "the arch of knowledge"
[4] "who cooked adam smith's dinner"
[5] "electronic dreams: how 1980s britain learned to love the computer"
[6] "invisible women: exposing data bias in a world designed for men"
[7] "the mismeasure of man (2nd ed)"
[8] "being wrong: adventures in the margin of error"
[9] "bad blood: secrets and lies in a silicon valley startup"
[10] "genesis and development of a scientific fact"
[11] "in the beginning was the worm: finding the secrets of life in a tiny hermaphrodite"
[12] "merchants of doubt"
[13] "harvey's heart: the discovery of blood circulation"
[14] "dark remedy: the impact of thalidomide and its revival as a vital medicine"
[15] "how emotions are made"
[16] "medical statistics at a glance"
[17] "the half-life of facts"
[18] "weapons of math destruction"
[19] "disease maps: epidemics on the ground"
[20] "the utopia of rules: on technology, stupidity, and the secret joys of bureaucracy"
[21] "how to lie with statistics"
[22] "\"clean code: a handbook of agile software craftsmanship\""
[23] "thinking, fast and slow"
[24] "the 7 deadly sins of psychology"
[25] "what tech calls thinking: an inquiry into the intellectual bedrock of silicon valley"
[26] "how do you know if you are making a difference? a practical handbook for public service organisations"
[27] "reckoning with risk: learning to live with uncertainty"
[28] "hybrid humans: dispatches from the frontiers of man and machine"
[29] "asking the right questions: a guide to critical thinking"
[30] "the alignment problem"
[31] "the devil you know - encounters in forensic psychiatry"
[32] "the end of alchemy: money, banking and the future of the global economy"
[33] "the checklist manifesto"
[34] "technofeudalism"
[35] "the geek manifesto"
[36] "'sapiens: a brief history of humankind' and 'homo deus: a brief history of tomorrow'"
[37] "never split the difference"
[38] "r for data science (2nd edition)"
[39] "field notes on science & nature"
[40] "how to write a lot" botw |>
mutate(Date = lubridate::dmy(Date)) |> # fixing publication dates
group_by(month = lubridate::floor_date(Date, unit = "month")) |>
summarise(mean_year = mean(as.numeric(Year), na.rm = T)) # average year of publication by month of botw# A tibble: 12 × 2
month mean_year
<date> <dbl>
1 2024-03-01 2003
2 2024-04-01 2016
3 2024-05-01 2011.
4 2024-06-01 2004.
5 2024-07-01 2012.
6 2024-08-01 1997
7 2024-09-01 2018
8 2024-10-01 2012
9 2024-11-01 2016.
10 2024-12-01 2010
11 2025-01-01 2017
12 2025-02-01 2014.Plots
Using matplotlib
import matplotlib.pyplot as plt
plt.hist(botw["Year"], bins = [1970, 1980, 1990, 2000, 2010, 2020])
plt.title("The KIND network BotW is biased towards newer books")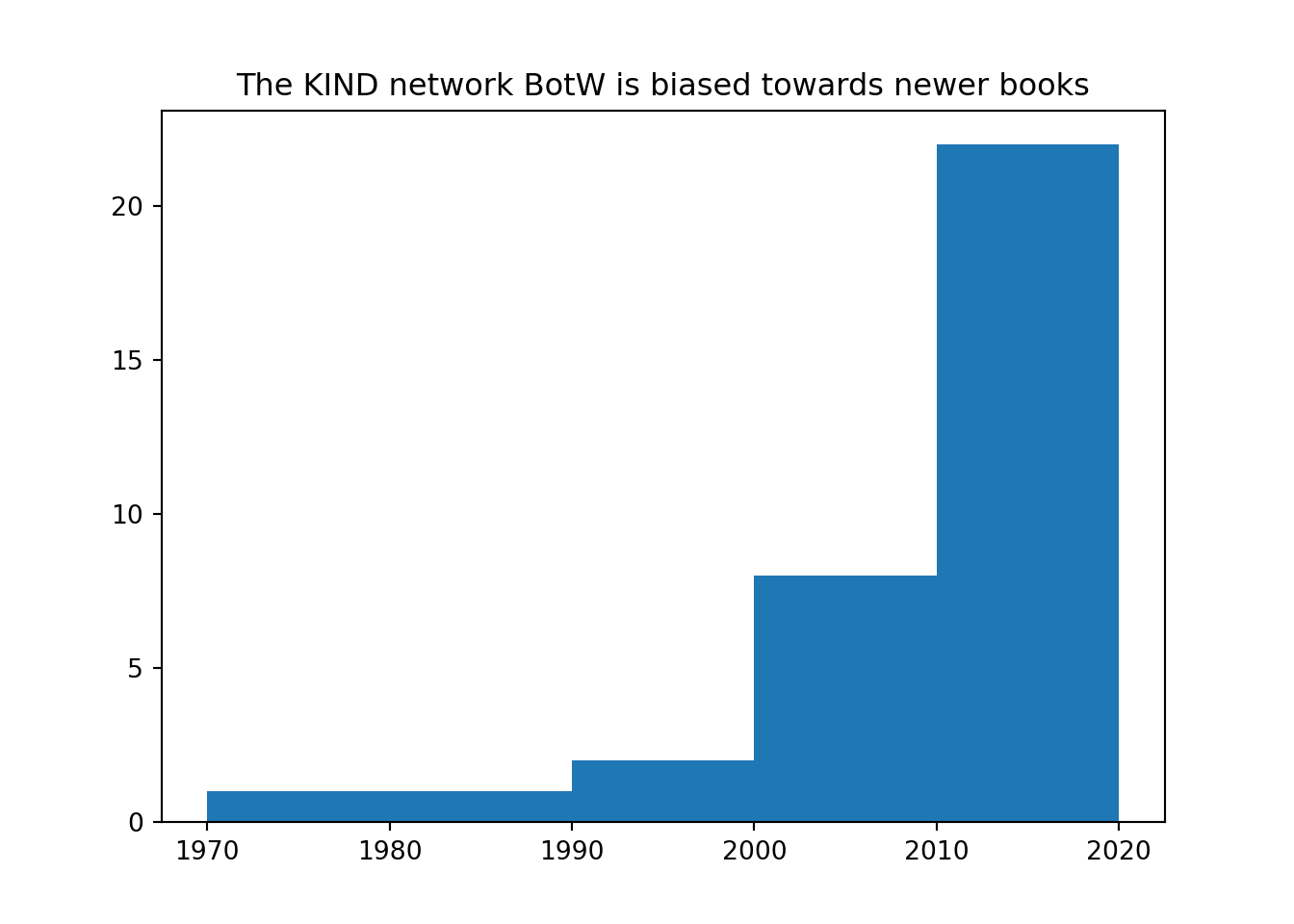
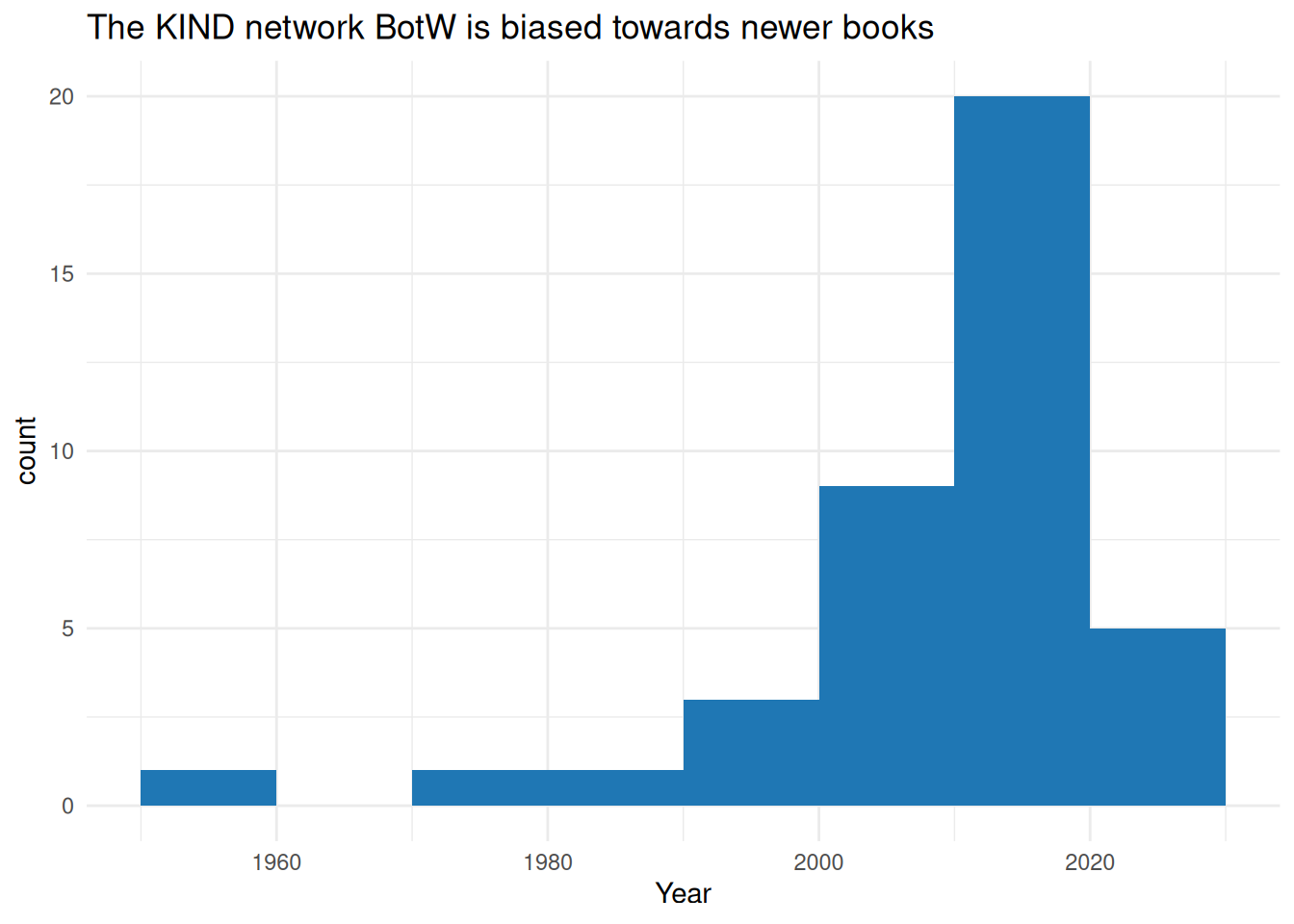
library(ggplot2)
botw |>
mutate(Year = readr::parse_number(Year)) |>
ggplot() +
geom_histogram(aes(x = Year), fill="#1F77B4", binwidth = 10, center = 1985) +
ggtitle("The KIND network BotW is biased towards newer books") +
theme_minimal()