An introduction to AI (…and why you might avoid that term)
AI/ML
beginner
Previous attendees have said…
- 75 previous attendees have left feedback
- 95% would recommend this session to a colleague
- 95% said that this session was pitched correctly

NoteThree random comments from previous attendees
- A great introduction, clearly explained that has improved my understanding of what AI is and what it can and can’t do.
- A good introduction to AI for someone who does not know much about it. I realised I am using AI which I wasn’t really aware of.
- Very Informative.
Welcome
- this session is 🌶: for beginners
- it aims to do two things:
- to suggest that the term AI is troublesome
- to introduce some of the different technologies that get lumped together as AI
What does AI mean to you?




AI exists in the popular imaginary - independent of the tech itself
Is AI…
- Over-hyped?
- Somewhere in between?
- Neglected?
- Other / don’t know
Hype
- There’s a lot of hype about AI at the moment (see this graph, and approx. 100 billion LinkedIn posts)
- Underneath the hype, there’s a lot of genuinely exciting stuff going on too
- That exciting stuff is likely to have some impact on health and care work
Why the hype matters
- hype leads to perverse incentives and malfeasance
- call any rubbish AI, and get paid for it
- that means that understanding what we mean by AI, and what tech calls AI, is important for practitioners
- there’s an industry out there that’s profiting from blurring the boundaries
- getting it wrong might be very important: different tech has different strengths and weaknesses
A philosophical question
- do submarines swim?
Motive
- The intelligence part of AI is as misleading as a swimming submarine
- There are lots of different technologies that currently fall under the AI umbrella
- Points 1. and 2. cause blurring of boundaries about what gets called AI
- That blurring matters in a practical way because of the hot hot hype

About this talk
Two linked problems:
- a worry about intelligence: based on the swimming submarine
- a worry about diversity: AI is several things, not just one thing
The Chinese room
Searle (1980)
“Suppose that I’m locked in a room and given a large batch of Chinese writing. Suppose furthermore (as is indeed the case) that I know no Chinese, either written or spoken, and that I’m not even confident that I could recognize Chinese writing”
However, he is supplied with a set of intelligible rules for manipulating these Chinese symbols
“火” is the opposite of “水”
“六” is more than “四”
Questions
- Does this poor bloke locked in a room understand the Chinese symbols?
- Now suppose that we start asking him questions (in English):
- Is “六” more than “四”?
- If so, respond with “是”. Otherwise respond “不”
Question
- Is understanding the same thing as being able to produce output in response to input?
- Searle (1980) - this is the difference between strong and weak AI
Back to nice safe words
- we usually don’t worry too much about what words like intelligence, understanding, etc really mean
- for most purposes, understanding something, and doing that thing, pretty well overlap
- AI, unfortunately, is an exception
- big difference between producing output and understanding here
Why does this matter?
- Because the current conversation around AI does violence to our usual understanding of basic terms (like intelligence)
- We need to do a bit of re-interpreting…
- …particularly because AI can do the input-output part really well
- (side effect) The Chinese Room is an excellent way of understanding what’s going on inside some of the current tech
The tech
- AI = big umbrella term
- More specific terms:
- Algorithms = rule-based ways of producing sensible output
- Expert systems = more sophisticated expertise-based production of output
- Machine learning = umbrella term for non-expertise-based production of output
- Large Language Models = a massively-succesful sub-species of machine learning
So what’s an algorithm?

{kind=link}
- Algorithm = rule (roughly)
- if something happens, do something
- made from expert input and evidence
An example algorithm
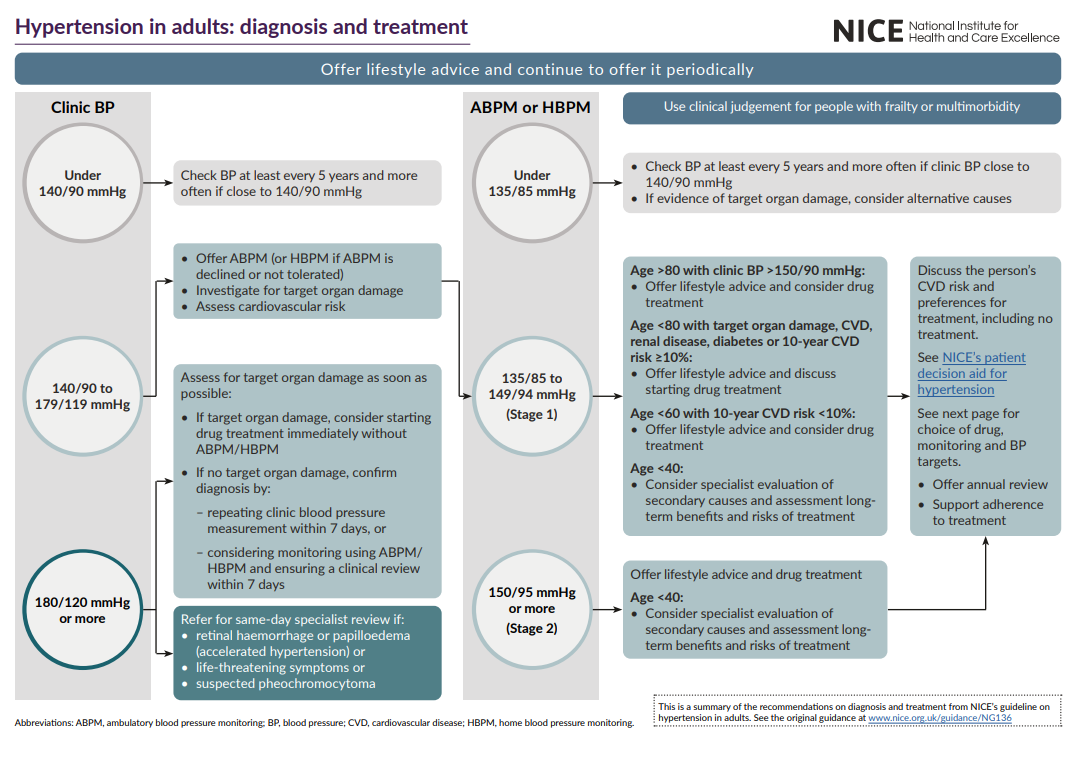
Related expertise-based tools
“See also…” references in indexes, library catalogues, wikipedia
- Brilliant 1996 Master’s dissertation looking at the state of “see also…” referencing in Ohio’s public libraries
How about something more complicated?
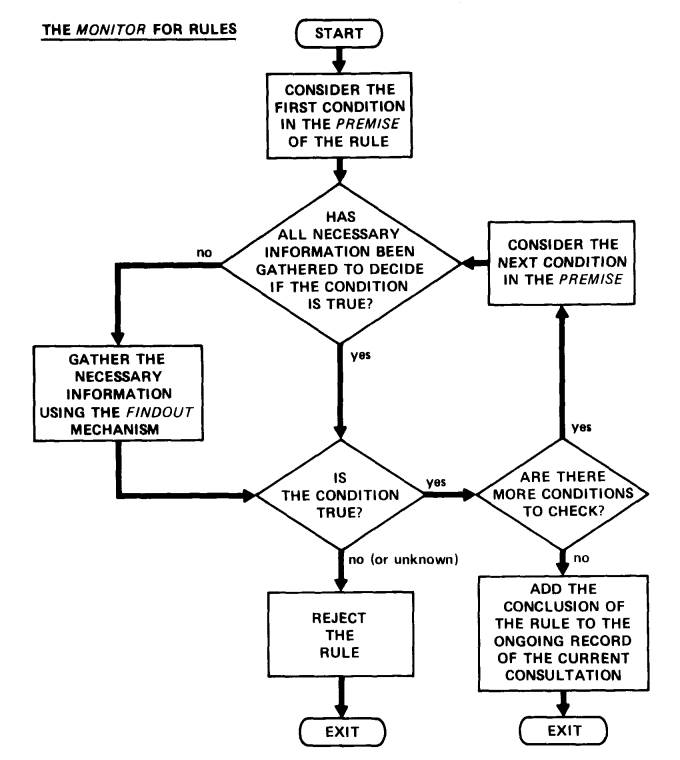
- one problem with algorithms: how to handle conflicting information?
- An expert system - MYCIN (Shortliffe and Buchanan 1975)
- designed to identify bacterial infections and suitable Rx
- 600 rules, supplied by experts
- asks users a series of clinical questions
- combines the answers using a (fairly simple) inference system
- able to manage some conflicting information - unlike simpler algorithms
Machine learning
- A next step: can we provide learning rules to a system, and let it figure out the details for itself?
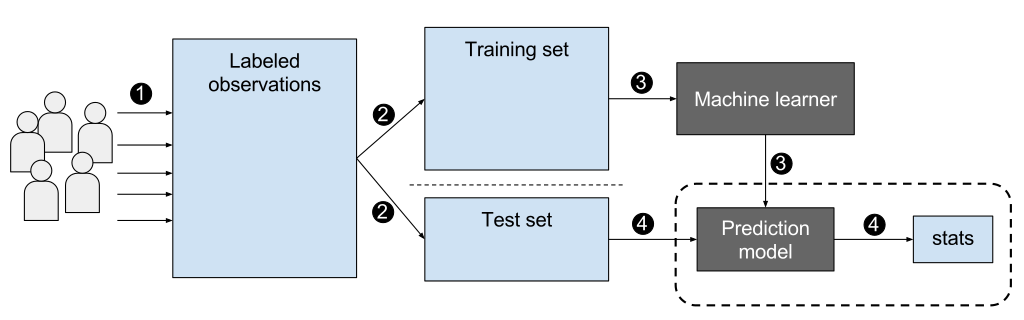
This is supervised learning
- supervision = labelled observations used for training and testing
- Lots of health examples with promising results:
- diabetic retinopathy (Mookiah et al. 2013)
- ECG (Aziz et al. 2021)
- fractures, melanoma, …
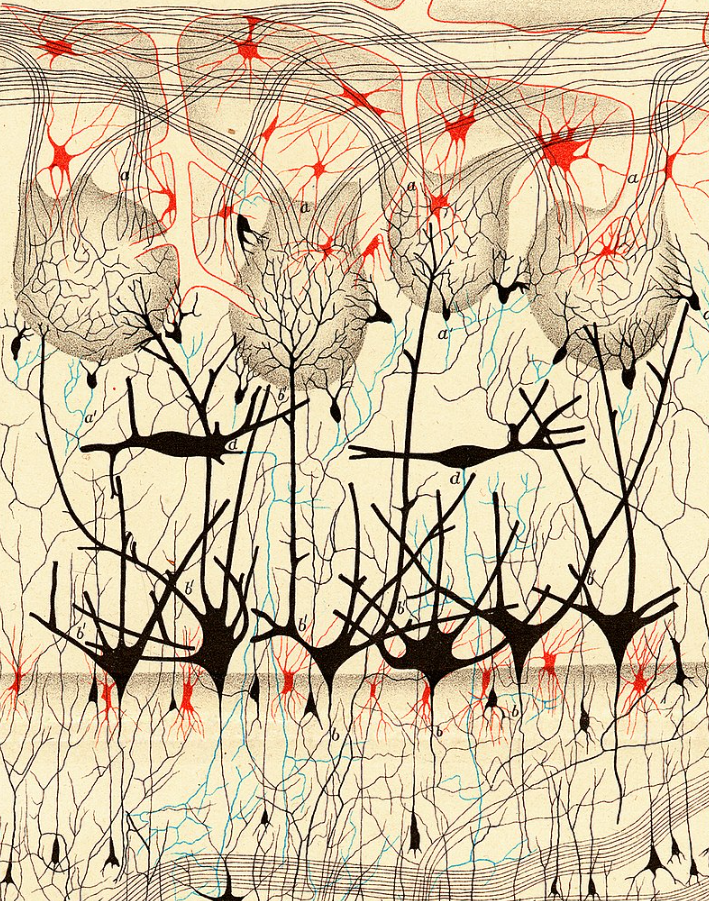
There’s a lot going on in that Machine learner box
- e.g. artificial neural networks (ANNs)
- ANNs can can potentially replicate any input-output transformation (learn anything, in other words)
- that capacity depends on complexity: simple units in complex arrangements
- we can’t draw simple conclusions about likely behaviour from this structure
Fashion MNIST
 + an example of a labelled dataset
+ an example of a labelled dataset
Labelling is hard
Producing labelled datasets is hard:
- generally must be very large
- generally requires expert classification
- must be done with great accuracy
- scale bar problem (Winkler et al. 2021)
- so dataset labelling is wildly expensive and thankless
- Is there a way of doing something similar without spending trillions classifying everything in the world by hand?
Unsupervised learning
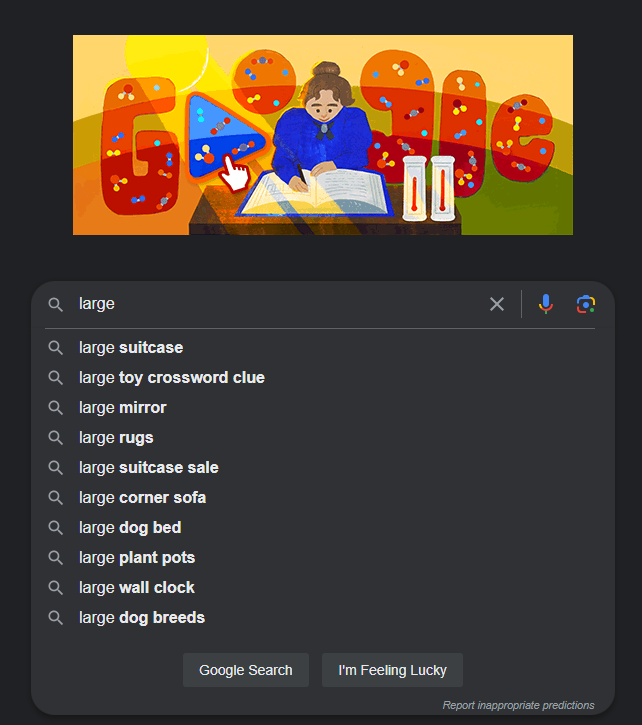
Unsupervised learning

Unsupervised learning
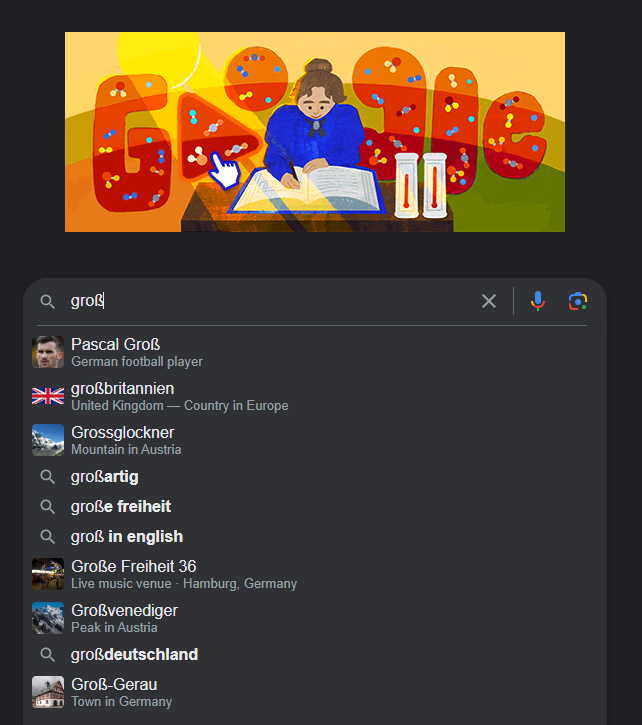
Unsupervised learning
- No-one is writing a list of possible searches starting with “Large…”
- Nor are they classifying searches into likely/unlikely, then training a model
- Instead, the model is looking at data (searches, language, location, trends) and calculating probabilities
Deep learning?
- The terminology gets confusing again at this point:
- some describe this as deep learning
- better to call this a language model
Transformers
![]()
Large language models
What if we were more ambitious with the scope of our language model?
- Find masses of language data
- chatGPT uses basically the whole web before September 2021
- Build a model capable of finding patterns in that data
- Attention model used in chatGPT (Vaswani et al. 2017)
- Allow the model to calculate probabilities based on those patterns
- lots of work going on at present allowing models to improve in response to feedback etc
Large language models
- superb at generating appropriate text, code, images, music…
- but production vs understanding
- e.g. hallucinations, phantom functions…
- training is extremely computationally expensive
- questions about inequality and regulatory moating
- no-one but FAANG-sized companies can afford to do this
- training is also surprisingly manual
- questions about inequality and regulatory moating
Ethics
- your web content, my model, my paycheque
- where’s the consent here?
- big serious worries about bias in some kinds of output
- rights violations via AI
- no settled questions around responsibility
- UK GDPR etc assume data is identifiable. That’s not true in LLMs.
Punchline
- On balance, while there’s hype here, there’s also lots of substance and interest
- LLMs have become much better at producing plausible output, across a greatly expanded area
- A strength: fantastic ways to speed-up experts
- A danger: LLMs excel at producing truth-like output
- But big serious legal and ethical trouble ahead - we’re not good at dealing with distributed responsibility
Thumbs-up for specificity
- many of the touted benefits are technology-specific
- e.g. if we want to understand why decisions are getting made in a particular way, an expert system is better than a LLM
- we should probably start asking “what do you mean by AI” whenever we’re trying to make decisions about it
Conclusion
- The intelligence part of AI is as misleading as a swimming submarine
- There are lots of different technologies that currently fall under the AI umbrella
- Points 1. and 2. cause blurring of boundaries about what gets called AI
- That blurring matters in a practical way for us in health and care
References
Aziz, Saira, Sajid Ahmed, and Mohamed-Slim Alouini. 2021. “ECG-Based Machine-Learning Algorithms for Heartbeat Classification.” Scientific Reports 11 (1). https://doi.org/10.1038/s41598-021-97118-5.
Mookiah, Muthu Rama Krishnan, U. Rajendra Acharya, Chua Kuang Chua, Choo Min Lim, E. Y. K. Ng, and Augustinus Laude. 2013. “Computer-Aided Diagnosis of Diabetic Retinopathy: A Review.” Computers in Biology and Medicine 43 (12): 2136–55. https://doi.org/10.1016/j.compbiomed.2013.10.007.
Searle, John R. 1980. “Minds, Brains, and Programs.” Behavioral and Brain Sciences 3 (3): 417–24. https://doi.org/10.1017/s0140525x00005756.
Shortliffe, Edward H., and Bruce G. Buchanan. 1975. “A Model of Inexact Reasoning in Medicine.” Mathematical Biosciences 23 (3-4): 351–79. https://doi.org/10.1016/0025-5564(75)90047-4.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, et al. 2017. Attention Is All You Need. https://doi.org/10.48550/ARXIV.1706.03762.
Winkler, Julia K., Katharina Sies, Christine Fink, et al. 2021. “Association Between Different Scale Bars in Dermoscopic Images and Diagnostic Performance of a Market-Approved Deep Learning Convolutional Neural Network for Melanoma Recognition.” European Journal of Cancer 145 (March): 146–54. https://doi.org/10.1016/j.ejca.2020.12.010.