can produce complex and sophisticated behaviours in a robust way
non-obvious relationships between structure and function
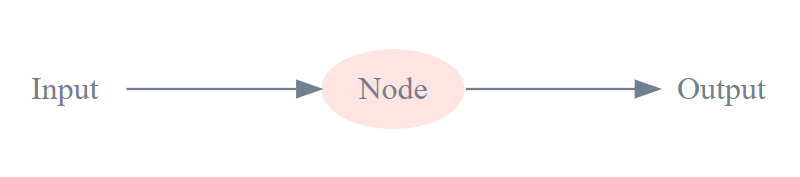
Machines: the node
Here’s a simple representation of a node, implemented in code, that we might find in a neural network:
Simple node representation
Machines: activation functions
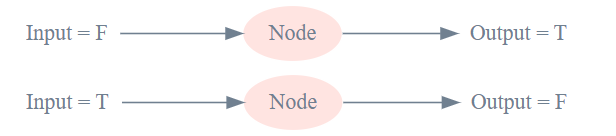
Here are some example input:output pairs for our node:
Node input:output pairs
there are lots of possible activation functions
a simple one: NOT
our node outputs TRUE when we input FALSE, and vice versa
This flexibility means that we can build networks of nodes (hence neural networks). Again, a very simple example:
Activation functions can be extremely simple
node<-function(input){!input}node(TRUE)
[1] FALSE
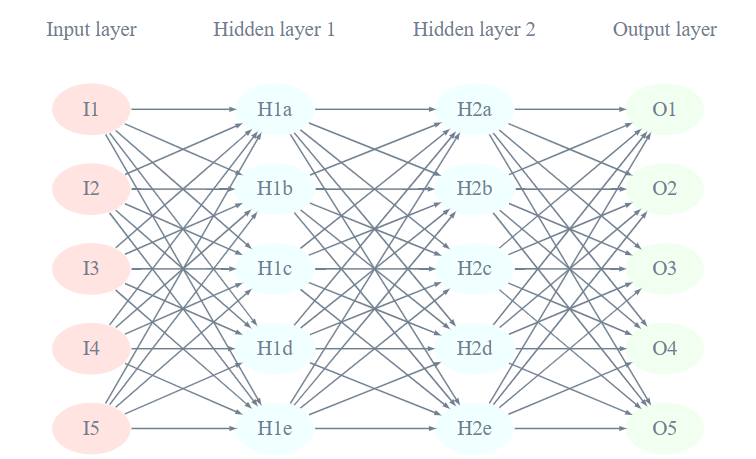
Machines: networks of nodes
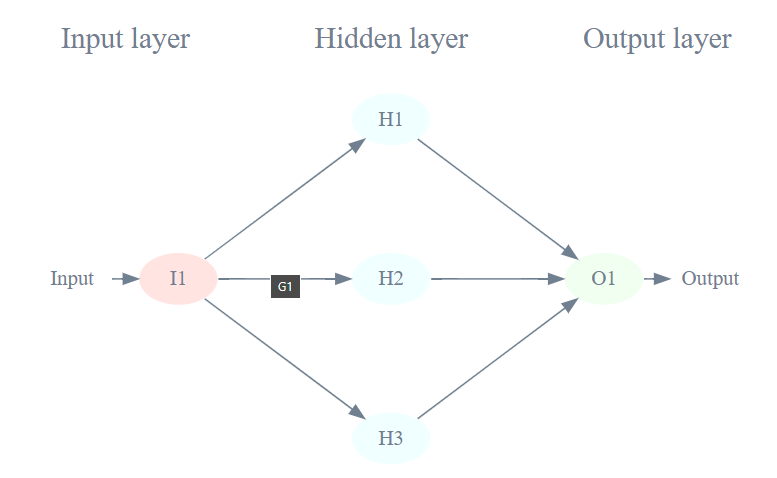
Networks of nodes
Machines: networks of nodes
nodes are usually found in networks
can produce complex and sophisticated behaviours in a robust way
again, non-obvious relationships between structure and function in artifical neural networks (ANN)
A user supplies some input. That input is fed into an input node(s), which processes the input, and produces three different outputs that are then fed into a second layer of nodes. Further processing happens in this hidden layer, leading to three outputs that are integrated together in a final output node that processes the outputs of the hidden layer into a single output.
training works by varying weights and biases across the network, and evaluating the overall response across the training data. Call that an epoch
LeCun initialization: In this method, you would follow a formula that considers the number of inputs and outputs to create random weights that represent a series of numbers, all with an equal probability of being the starting weight.
Xavier initialization: This method is similar to the LeCun method but is used in Keras and takes a square root of the initialization values you would get from a LeCun method.
He initialization: A method useful for deep learning, He initialization uses an activation function to assign weights.
{kind=link}
.jpg){kind=link}


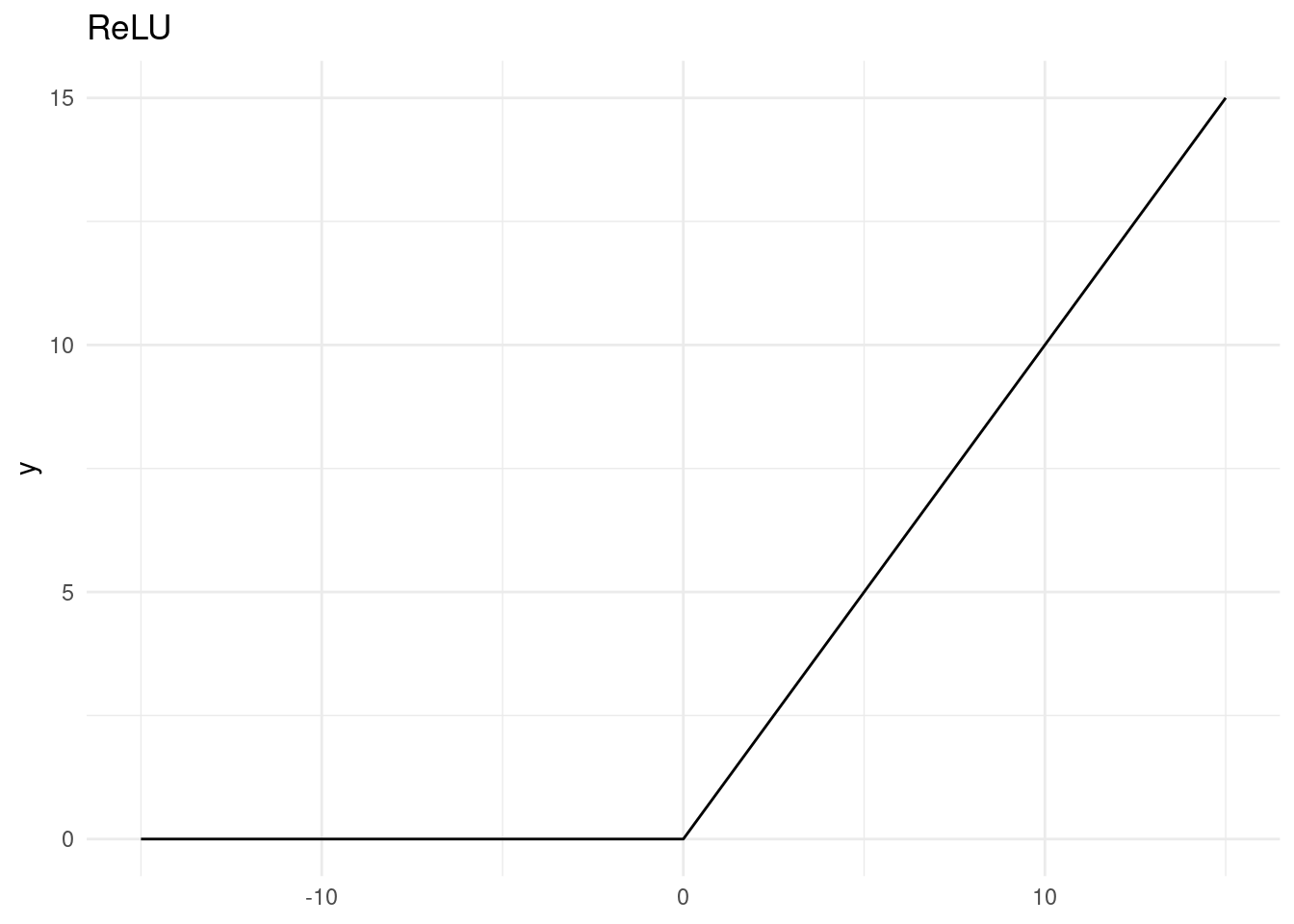



{kind=link}